CPUのパイプライン化
これまでの章では、 同時に1つの命令を実行するCPUを実装しました。 高機能なCPUを実装するのは面白いですが、 プログラムの実行が遅くてはいけません。 機能を増やす前に、一度性能のことを考えてみましょう。
CPUの速度
CPUの性能指標は、 例えば消費電力や実行速度が考えられます。 本章では、プログラムの実行速度を考えます。
CPUの性能を考える
性能の比較にはクロック周波数やコア数などが用いられますが、 プログラムの実行速度を比較する場合、 プログラムの実行にかかる時間のみが絶対的な指標になります。 プログラムの実行時間は、次のような式で表せます (図1)

▲図1: CPU性能方程式
それぞれの用語の定義は次の通りです。
- CPU時間 (CPU time)
- プログラムの実行のためにCPUが費やした時間
- 実行命令数
- プログラムの実行で実行される命令数
- CPI (Clock cycles Per Instruction)
- プログラム全体またはプログラムの一部分の命令を実行した時の1命令当たりの平均クロック・サイクル数
- クロック周波数 (clock rate)
- クロック・サイクル時間(clock cycle time)の逆数
クロック・サイクル時間は、クロックが`0`→`1`→`0`になる周期のこと
今のところ、CPUは命令をスキップしたり無駄に実行することはありません。 そのため、実行命令数は、プログラムを1命令ずつ順に実行していった時の実行命令数になります。
CPIを計測するためには、 何の命令にどれだけのクロック・サイクル数がかかるかと、 それぞれの命令の割合が必要です。 今のところ、 メモリにアクセスする命令は3 ~ 4クロック、 それ以外の命令は1クロックで実行されます。 命令の割合は考えないでおきます。
クロック周波数は、CPUの回路のクリティカルパスの長さによって決まります。 クリティカルパスとは、組み合わせ回路の中で最も大きな遅延を持つ経路のことです。
実行速度を上げる方法を考える
CPU性能方程式の各項に注目すると、 CPU時間を減らすためには、 実行命令数を減らすか、 CPIを減らすか、 クロック周波数を増大させる必要があります。
実行命令数に注目する
実行命令数を減らすためには、 コンパイラによる最適化でプログラムの命令数を減らすソフトウェア的な方法と、 命令セットアーキテクチャ(ISA)を変更することで必要な命令数を減らす方法が存在します。 どちらも本書の目的とするところではないので、検討しません[1]。
CPIに注目する
CPIを減らすためには、 例えばどの命令も1クロックで実行してしまうという方法が考えられます。 しかし、そのために論理回路を大きくすると、 その分クリティカルパスが長くなってしまう場合があります。 また、1クロックに1命令しか実行しない場合、 どう頑張ってもCPIは1より小さくなりません。
CPIをより効果的に減らすためには、 1クロックで1つ以上の命令を実行開始し、 1つ以上の命令を実行完了すればいいです。 これを実現する手法として、 スーパースカラやアウトオブオーダー実行が存在します。 これらの手法はずっと後の章で解説、実装します。
クロック周波数に注目する
クロック周波数を増大させるには、 クリティカルパスの長さを短くする必要があります。
今のところ、CPUは計算命令を1クロック(シングルサイクル)で実行します。 例えばADD命令を実行するとき、 FIFOに保存されたADD命令をデコードし、 命令のビット列をもとにレジスタの値を選択し、 ALUで足し算を実行し、 その結果をレジスタにライトバックします。 これらを1クロックで実行するということは、 命令が保存されている32ビットのレジスタと32*64ビットのレジスタファイルを入力に、 64ビットのADD演算の結果を出力する組み合わせ回路が存在するということです。 この回路は大変に段数の深い組み合わせ回路を必要とし、 長いクリティカルパスを生成する原因になります。
クロック周波数を増大させるもっとも単純な方法は、 命令の処理をいくつかのステージ(段)に分割し、 複数クロックで1つの命令を実行することです。 複数のクロック・サイクルで命令を実行することから、 この形式のCPUはマルチサイクルCPUと呼びます。

▲図2: 命令の実行 (マルチサイクル)
命令の処理をいくつかのステージに分割すると、 それに合わせて回路の深さが軽減され、 クロック周波数を増大させられます。
図2では、 1つの命令を3クロック(ステージ)で実行しています。 3クロックもかかるのであれば、 CPIが3倍になり、 CPU時間が増えてしまいそうです。 しかし、処理を均等な3ステージに分割できた場合、 クロック周波数は3分の1になる[2]ため、 それほどCPU時間は増えません。
しかし、CPIがステージ分だけ増大してしまうのは問題です。 この問題は、命令の処理を、まるで車の組立のように流れ作業で行うことで緩和できます(図3)。 このような処理のことを、パイプライン処理と呼びます。

▲図3: 命令の実行 (パイプライン処理)
本章では、 CPUをパイプライン化することで性能の向上を図ります。
パイプライン処理のステージを考える
具体的に処理をどのようなステージに分割してパイプライン処理を実現すればいいでしょうか? これを考えるために、第3章の最初で検討したCPUの動作を振り返ります。 第3章では、CPUの動作を次のように順序付けしました。
- PCに格納されたアドレスにある命令をフェッチする
- 命令を取得したらデコードする
- 計算で使用するデータを取得する (レジスタの値を取得したり、即値を生成する)
- 計算する命令の場合、計算を行う
- メモリにアクセスする命令の場合、メモリ操作を行う
- 計算やメモリアクセスの結果をレジスタに格納する
- PCの値を次に実行する命令のアドレスに設定する
もう少し大きな処理単位に分割しなおすと、 次の5つの処理(ステージ)を構成できます。 ステージ名の後ろに、それぞれ対応する上のリストの処理の番号を記載しています。
- IF (Instruction Fetch) ステージ (1)
- メモリから命令をフェッチします。
フェッチした命令をIDステージに受け渡します。 - ID (Instruction Decode) ステージ (2、3)
- 命令をデコードし、制御フラグと即値を生成します。
生成したデータをEXステージに渡します。 - EX (EXecute) ステージ (3、4)
- 制御フラグ、即値、レジスタの値を利用し、ALUで計算します。
分岐判定やジャンプ先の計算も行い、生成したデータをMEMステージに渡します。 - MEM (MEMory) ステージ (5、7)
- メモリにアクセスする命令とCSR命令を処理します。
分岐命令かつ分岐が成立する、ジャンプ命令である、またはトラップが発生するとき、 IF、ID、EXステージにある命令を無効化して、ジャンプ先をIFステージに伝えます。 メモリのロード、CSRの読み込み結果をWBステージに渡します。 - WB (WriteBack) ステージ (6)
- ALUの演算結果、メモリやCSRの読み込み結果など、命令の処理結果をレジスタに書き込みます。
MEMステージではジャンプするときにIF、ID、EXステージにある命令を無効化します。 これは、IF、ID、EXステージにある命令は、 ジャンプによって実行されない命令になるためです。 パイプラインのステージにある命令を無効化することを、 パイプラインをフラッシュ(flush)すると呼びます。
IF、ID、EX、MEM、WBの5段の構成を、 5段パイプライン(Five Stage Pipeline)と呼ぶことがあります。
CSRをMEMステージで処理する
上記の5段のパイプライン処理では、CSRの処理をMEMステージで行っています。 これはいったいなぜでしょうか?
CPUにはECALL命令による例外しか実装してしないため、 EXステージでCSRの処理を行ってしまっても問題ありません。 しかし、他の例外、例えばメモリアクセスに伴う例外を実装するとき、 問題が生じます。
メモリアクセスに起因する例外が発生するのはMEMステージです。 このとき、EXステージでCSRの処理を行っていて、 EXステージに存在する命令がmtvecレジスタに書き込むCSRRW命令だった場合、 本来はMEMステージで発生した例外によって実行されないはずであるCSRRW命令によって、 既にmtvecレジスタが書き換えられているかもしれません。 これを復元する処理を書くことはできますが、 MEMステージ以降でCSRを処理することでもこの事態を回避できるため、 MEMステージでCSRを処理しています。
パイプライン処理の実装
ステージに分割する準備をする
それでは、CPUをパイプライン化します。
パイプライン処理では、 複数のステージがそれぞれ違う命令を処理します。 そのため、それぞれのステージのために、 現在処理している命令を保持するためのレジスタ(パイプラインレジスタ)を用意します。
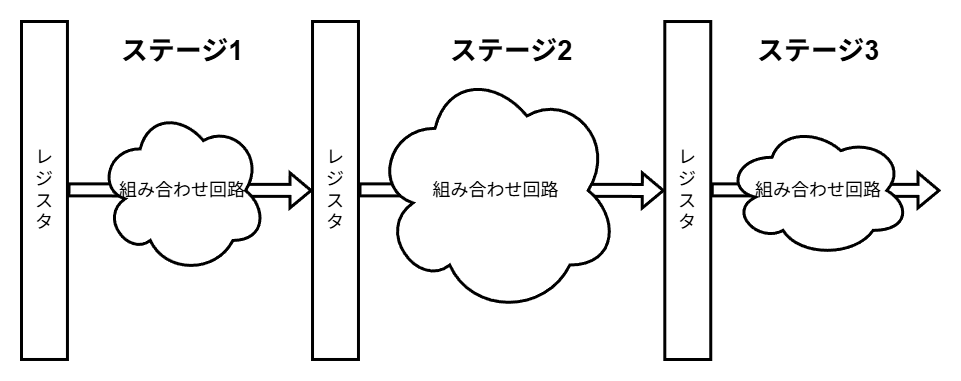
▲図4: パイプライン処理の概略図
まず、処理を複数ステージに分割する前に、 既存の変数の名前を変更します。
coreモジュールでは、 命令をフェッチする処理に使う変数の名前の先頭にif_、 FIFOから取り出した命令の情報を表す変数の名前の先頭にinst_をつけています。
命令をフェッチする処理はIFステージに該当するため、 if_から始まる変数はこのままで問題ありません。 しかし、inst_から始まる変数は、 CPUの処理を複数ステージに分けたとき、 どのステージの変数か分からなくなります。 IFステージの次はIDステージであるため、 変数がIDステージのものであることを示す名前に変えてしまいます。
▼リスト7.1: 変数名を変更する (core.veryl) 差分をみる
let ids_valid : logic = if_fifo_rvalid;
var ids_is_new : logic ; // 命令が現在のクロックで供給されたかどうか
let ids_pc : Addr = if_fifo_rdata.addr;
let ids_inst_bits: Inst = if_fifo_rdata.bits;
var ids_ctrl : InstCtrl;
var ids_imm : UIntX ;
inst_valid、inst_is_new、inst_pc、 inst_bits、inst_ctrl、inst_immの名前をリスト1のように変更します。 定義だけではなく、変数を使用しているところもすべて変更してください。
FIFOを作成する
命令フェッチ処理とそれ以降の処理は、それぞれ独立して動作しています。 実は既にCPUは、IFとIDステージ(命令フェッチ以外の処理を行うステージ)の2ステージのパイプライン処理を行っています。
IFステージとIDステージはFIFOで区切られており、 FIFOのレジスタを経由して命令の受け渡しを行います。 これと同様に、 5ステージのパイプライン処理の実装では、 それぞれのステージをFIFOで接続します(図5)。 ただし、FIFOのサイズは1とします。 この場合、FIFOはただの1つのレジスタです。
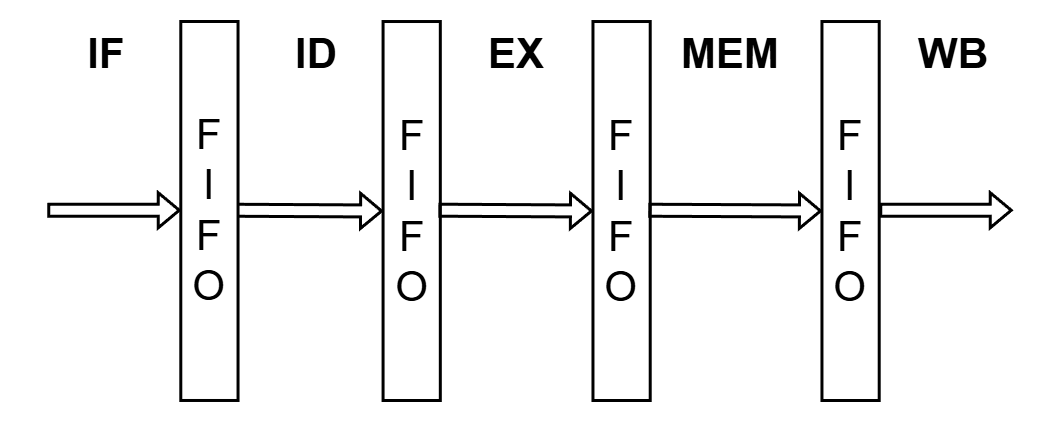
▲図5: FIFOを利用したパイプライン処理
IFからIDへのFIFOは存在するため、 IDからEX、EXからMEM、MEMからWBへのFIFOを作成します。
構造体の定義
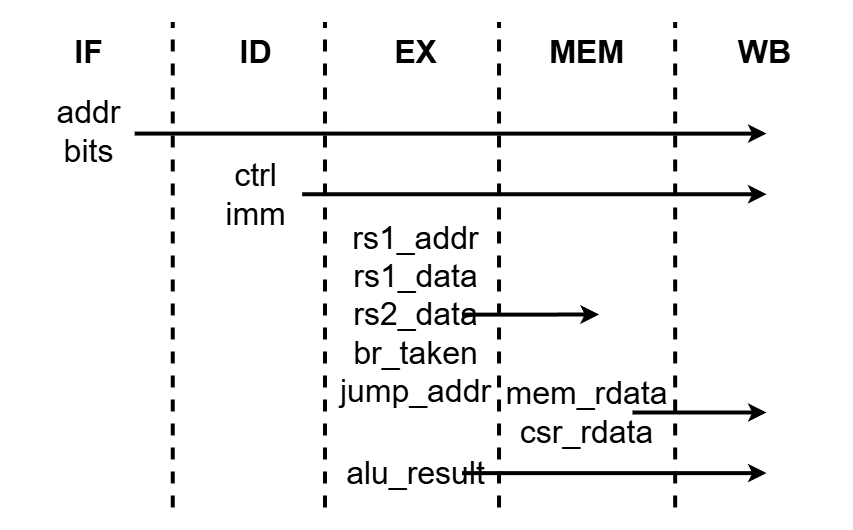
▲図6: 構造体のフィールドの生存区間
まず、FIFOに格納するデータの型を定義します。 それぞれのフィールドが存在する区間は図6の通りです。
▼リスト7.2: ID → EXの間のFIFOのデータ型 (core.veryl) 差分をみる
struct exq_type {
addr: Addr ,
bits: Inst ,
ctrl: InstCtrl,
imm : UIntX ,
}
IDステージは、IFステージから命令のアドレスと命令のビット列を受け取ります。 命令のビット列をデコードして、制御フラグと即値を生成し、EXステージに渡します(リスト2)。
▼リスト7.3: EX → MEMの間のFIFOのデータ型 (core.veryl) 差分をみる
struct memq_type {
addr : Addr ,
bits : Inst ,
ctrl : InstCtrl ,
imm : UIntX ,
alu_result: UIntX ,
rs1_addr : logic <5>,
rs1_data : UIntX ,
rs2_data : UIntX ,
br_taken : logic ,
jump_addr : Addr ,
}
EXステージは、IDステージで生成された制御フラグと即値を受け取ります。 整数演算命令のとき、レジスタの値を使って計算します。 分岐命令のとき、分岐判定を行います。 CSRやメモリアクセスでrs1とrs2を利用するため、 演算の結果とともにMEMステージに渡します(リスト3)。
▼リスト7.4: MEM → WBの間のFIFOのデータ型 (core.veryl) 差分をみる
struct wbq_type {
addr : Addr ,
bits : Inst ,
ctrl : InstCtrl,
imm : UIntX ,
alu_result: UIntX ,
mem_rdata : UIntX ,
csr_rdata : UIntX ,
}
MEMステージは、 メモリのロード結果とCSRの読み込みデータを生成し、 WBステージに渡します(リスト4)。
WBステージでは、 命令がライトバックする命令のとき、 即値、ALUの計算結果、メモリのロード結果、CSRの読み込みデータから1つを選択し、 レジスタに値を書き込みます。
構造体のフィールドの生存区間が図6のようになっている理由が分かったでしょうか?
FIFOのインスタンス化
FIFOと接続するための変数を定義し、FIFOをインスタンス化します (リスト5、リスト6)。 DATA_TYPEパラメータには先ほど作成した構造体を設定します。 FIFOのデータ個数は1であるため、WIDTHパラメータには1を設定します[3]。 mem_wb_fifoのflushは0にしています。
▼リスト7.5: FIFOと接続するための変数を定義する (core.veryl) 差分をみる
// ID -> EXのFIFO
var exq_wready: logic ;
var exq_wvalid: logic ;
var exq_wdata : exq_type;
var exq_rready: logic ;
var exq_rvalid: logic ;
var exq_rdata : exq_type;
// EX -> MEMのFIFO
var memq_wready: logic ;
var memq_wvalid: logic ;
var memq_wdata : memq_type;
var memq_rready: logic ;
var memq_rvalid: logic ;
var memq_rdata : memq_type;
// MEM -> WBのFIFO
var wbq_wready: logic ;
var wbq_wvalid: logic ;
var wbq_wdata : wbq_type;
var wbq_rready: logic ;
var wbq_rvalid: logic ;
var wbq_rdata : wbq_type;
▼リスト7.6: FIFOのインスタンス化 (core.veryl) 差分をみる
inst id_ex_fifo: fifo #(
DATA_TYPE: exq_type,
WIDTH : 1 ,
) (
clk ,
rst ,
flush : control_hazard,
wready: exq_wready ,
wvalid: exq_wvalid ,
wdata : exq_wdata ,
rready: exq_rready ,
rvalid: exq_rvalid ,
rdata : exq_rdata ,
);
inst ex_mem_fifo: fifo #(
DATA_TYPE: memq_type,
WIDTH : 1 ,
) (
clk ,
rst ,
flush : control_hazard,
wready: memq_wready ,
wvalid: memq_wvalid ,
wdata : memq_wdata ,
rready: memq_rready ,
rvalid: memq_rvalid ,
rdata : memq_rdata ,
);
inst mem_wb_fifo: fifo #(
DATA_TYPE: wbq_type,
WIDTH : 1 ,
) (
clk ,
rst ,
flush : 0 ,
wready: wbq_wready,
wvalid: wbq_wvalid,
wdata : wbq_wdata ,
rready: wbq_rready,
rvalid: wbq_rvalid,
rdata : wbq_rdata ,
);
IFステージを実装する
まず、IFステージを実装します。 ...といっても、 既にIFステージ(=命令フェッチ処理)は独立に動くものとして実装されているため、 手を加える必要はありません。
リスト7のようなコメントを挿入すると、 ステージの処理を書いている区間が分かりやすくなります。 ID、EX、MEM、WBステージを実装するときにも同様のコメントを挿入し、 ステージの処理のコードをまとまった場所に配置しましょう。
▼リスト7.7: IFステージが始まることを示すコメントを挿入する (core.veryl) 差分をみる
///////////////////////////////// IF Stage /////////////////////////////////
var if_pc : Addr ;
IDステージを実装する
IDステージでは、命令をデコードします。 既にids_ctrlとids_immには、 デコード結果の制御フラグと即値が割り当てられているため、 既存のコードの変更は必要ありません。
デコード結果はEXステージに渡します。 EXステージにデータを渡すには、 exq_wdataにデータを割り当てます (リスト8)。
▼リスト7.8: EXステージに値を渡す (core.veryl) 差分をみる
always_comb {
// ID -> EX
if_fifo_rready = exq_wready;
exq_wvalid = if_fifo_rvalid;
exq_wdata.addr = if_fifo_rdata.addr;
exq_wdata.bits = if_fifo_rdata.bits;
exq_wdata.ctrl = ids_ctrl;
exq_wdata.imm = ids_imm;
}
IDステージにある命令は、 EXステージが命令を受け入れられるとき(exq_wready)、 IDステージを完了してEXステージに処理を進められます。 この仕組みは、 if_fifo_rreadyにexq_wreadyを割り当てることで実現できます。
最後に、命令が現在のクロックで供給されたかどうかを示す変数id_is_newは必要ないため削除します (リスト9)。
▼リスト7.9: ids_is_newを削除する (core.veryl) 差分をみる
var ids_is_new : logic ;
EXステージを実装する
EXステージでは、 整数演算命令のときはALUで計算し、 分岐命令のときは分岐判定を行います。
まず、EXステージに存在する命令の情報をexq_rdataから取り出します(リスト10)。
▼リスト7.10: 変数の定義 (core.veryl) 差分をみる
let exs_valid : logic = exq_rvalid;
let exs_pc : Addr = exq_rdata.addr;
let exs_inst_bits: Inst = exq_rdata.bits;
let exs_ctrl : InstCtrl = exq_rdata.ctrl;
let exs_imm : UIntX = exq_rdata.imm;
次に、EXステージで扱う変数の名前を変更します。 変数の名前にexs_をつけます (リスト11)。
▼リスト7.11: 変数名を変更する (core.veryl) 差分をみる
// レジスタ番号
let exs_rs1_addr: logic<5> = exs_inst_bits[19:15];
let exs_rs2_addr: logic<5> = exs_inst_bits[24:20];
// ソースレジスタのデータ
let exs_rs1_data: UIntX = if exs_rs1_addr == 0 ? 0 : regfile[exs_rs1_addr];
let exs_rs2_data: UIntX = if exs_rs2_addr == 0 ? 0 : regfile[exs_rs2_addr];
// ALU
var exs_op1 : UIntX;
var exs_op2 : UIntX;
var exs_alu_result: UIntX;
always_comb {
case exs_ctrl.itype {
InstType::R, InstType::B: {
exs_op1 = exs_rs1_data;
exs_op2 = exs_rs2_data;
}
InstType::I, InstType::S: {
exs_op1 = exs_rs1_data;
exs_op2 = exs_imm;
}
InstType::U, InstType::J: {
exs_op1 = exs_pc;
exs_op2 = exs_imm;
}
default: {
exs_op1 = 'x;
exs_op2 = 'x;
}
}
}
inst alum: alu (
ctrl : exs_ctrl ,
op1 : exs_op1 ,
op2 : exs_op2 ,
result: exs_alu_result,
);
var exs_brunit_take: logic;
inst bru: brunit (
funct3: exs_ctrl.funct3,
op1 : exs_op1 ,
op2 : exs_op2 ,
take : exs_brunit_take,
);
最後に、MEMステージに命令とデータを渡します。 MEMステージにデータを渡すために、 memq_wdataにデータを割り当てます (リスト12)。
▼リスト7.12: MEMステージにデータを渡す (core.veryl) 差分をみる
always_comb {
// EX -> MEM
exq_rready = memq_wready;
memq_wvalid = exq_rvalid;
memq_wdata.addr = exq_rdata.addr;
memq_wdata.bits = exq_rdata.bits;
memq_wdata.ctrl = exq_rdata.ctrl;
memq_wdata.imm = exq_rdata.imm;
memq_wdata.rs1_addr = exs_rs1_addr;
memq_wdata.rs1_data = exs_rs1_data;
memq_wdata.rs2_data = exs_rs2_data;
memq_wdata.alu_result = exs_alu_result;
← ジャンプ命令、または、分岐命令かつ分岐が成立するとき、1にする
memq_wdata.br_taken = exs_ctrl.is_jump || inst_is_br(exs_ctrl) && exs_brunit_take;
memq_wdata.jump_addr = if inst_is_br(exs_ctrl) ? exs_pc + exs_imm : exs_alu_result & ~1;
}
br_takenには、 ジャンプ命令かどうか、または分岐命令かつ分岐が成立するか、 という条件を割り当てます。 jump_addrには、 分岐命令、またはジャンプ命令のジャンプ先を割り当てます。 MEMステージではこれを利用してジャンプと分岐を処理します。
EXステージにある命令は、 MEMステージが命令を受け入れられるとき(memq_wready)、 EXステージを完了してMEMステージに処理を進められます。 この仕組みは、 exq_rreadyにmemq_wreadyを割り当てることで実現できます。
MEMステージを実装する
MEMステージでは、メモリにアクセスする命令とCSR命令を処理します。 また、ジャンプ命令、分岐命令かつ分岐が成立、またはトラップが発生するとき、 次に実行する命令のアドレスを変更します。
ロードストア命令でメモリにアクセスしているとき、 EXステージからMEMステージに別の命令の処理を進めることはできず、 パイプライン処理は止まってしまいます。 パイプライン処理を進められない状態のことをパイプラインハザード(pipeline hazard)と呼びます。
まず、MEMステージに存在する命令の情報をmemq_rdataから取り出します(リスト13)。 MEMステージでは、csrunitモジュールに、 命令が現在のクロックでMEMステージに供給されたかどうかの情報を渡します。 そのため、変数mem_is_newを定義しています。
▼リスト7.13: 変数の定義 (core.veryl) 差分をみる
var mems_is_new : logic ;
let mems_valid : logic = memq_rvalid;
let mems_pc : Addr = memq_rdata.addr;
let mems_inst_bits: Inst = memq_rdata.bits;
let mems_ctrl : InstCtrl = memq_rdata.ctrl;
let mems_rd_addr : logic <5> = mems_inst_bits[11:7];
mem_is_newには、id_is_newの更新に利用していたコードを利用します(リスト14)。
▼リスト7.14: mem_is_newの更新 (core.veryl) 差分をみる
always_ff {
if_reset {
mems_is_new = 0;
} else {
if memq_rvalid {
mems_is_new = memq_rready;
} else {
mems_is_new = 1;
}
}
}
次に、MEMモジュールで使う変数に合わせて、 memunitモジュールとcsrunitモジュールのポートに割り当てている変数名を変更します (リスト15)。
▼リスト7.15: 変数名を変更する (core.veryl) 差分をみる
inst memu: memunit (
clk ,
rst ,
valid : mems_valid ,
is_new: mems_is_new ,
ctrl : mems_ctrl ,
addr : memq_rdata.alu_result,
rs2 : memq_rdata.rs2_data ,
rdata : memu_rdata ,
stall : memu_stall ,
membus: d_membus ,
);
var csru_rdata : UIntX;
var csru_raise_trap : logic;
var csru_trap_vector: Addr ;
inst csru: csrunit (
clk ,
rst ,
valid : mems_valid ,
pc : mems_pc ,
ctrl : mems_ctrl ,
rd_addr : mems_rd_addr ,
csr_addr: mems_inst_bits[31:20],
rs1 : if mems_ctrl.funct3[2] == 1 && mems_ctrl.funct3[1:0] != 0 ?
{1'b0 repeat XLEN - $bits(memq_rdata.rs1_addr), memq_rdata.rs1_addr} // rs1を0で拡張する
:
memq_rdata.rs1_data
,
rdata : csru_rdata ,
raise_trap : csru_raise_trap ,
trap_vector: csru_trap_vector,
);
フェッチ先が変わったことを表す変数control_hazardと、 新しいフェッチ先を示す信号control_hazard_pc_nextでは、 EXステージで計算したデータとCSRステージのトラップ情報を利用します (リスト16)。
▼リスト7.16: ジャンプの判定処理 (core.veryl) 差分をみる
always_comb {
control_hazard = mems_valid && (csru_raise_trap || mems_ctrl.is_jump || memq_rdata.br_taken);
control_hazard_pc_next = if csru_raise_trap ? csru_trap_vector : memq_rdata.jump_addr;
}
ジャンプ命令の後ろの余計な命令を実行しないために、 control_hazardが1になったとき、 ID、EX、MEMステージに命令を供給するFIFOをフラッシュします。 control_hazardが1になるとき、 MEMステージの処理は完了しています。 後述しますが、WBステージの処理は必ず1クロックで終了します。 そのため、フラッシュするとき、 MEMステージにある命令は必ずWBステージに移動します。
最後に、WBステージに命令とデータを渡します(リスト17)。 WBステージにデータを渡すために、 wbq_wdataにデータを割り当てます
▼リスト7.17: WBステージにデータを渡す (core.veryl) 差分をみる
always_comb {
// MEM -> WB
memq_rready = wbq_wready && !memu_stall;
wbq_wvalid = memq_rvalid && !memu_stall;
wbq_wdata.addr = memq_rdata.addr;
wbq_wdata.bits = memq_rdata.bits;
wbq_wdata.ctrl = memq_rdata.ctrl;
wbq_wdata.imm = memq_rdata.imm;
wbq_wdata.alu_result = memq_rdata.alu_result;
wbq_wdata.mem_rdata = memu_rdata;
wbq_wdata.csr_rdata = csru_rdata;
}
MEMステージにある命令は、 memunitモジュールが処理中ではなく(!memy_stall)、 WBステージが命令を受け入れられるとき(wbq_wready)、 MEMステージを完了してWBステージに処理を進められます。 この仕組みは、memq_rreadyとwbq_wvalidを確認してください。
WBステージを実装する
WBステージでは、命令の結果をレジスタにライトバックします。 WBステージが完了したら命令の処理は終わりなので、命令を破棄します。
まず、WBステージに存在する命令の情報をwbq_rdataから取り出します (リスト18)。
▼リスト7.18: 変数の定義 (core.veryl) 差分をみる
let wbs_valid : logic = wbq_rvalid;
let wbs_pc : Addr = wbq_rdata.addr;
let wbs_inst_bits: Inst = wbq_rdata.bits;
let wbs_ctrl : InstCtrl = wbq_rdata.ctrl;
let wbs_imm : UIntX = wbq_rdata.imm;
次に、WBステージで扱う変数名を変更します。 変数名にwbs_をつけます (リスト19)。
▼リスト7.19: 変数名を変更する (core.veryl) 差分をみる
let wbs_rd_addr: logic<5> = wbs_inst_bits[11:7];
let wbs_wb_data: UIntX = switch {
wbs_ctrl.is_lui : wbs_imm,
wbs_ctrl.is_jump: wbs_pc + 4,
wbs_ctrl.is_load: wbq_rdata.mem_rdata,
wbs_ctrl.is_csr : wbq_rdata.csr_rdata,
default : wbq_rdata.alu_result
};
always_ff {
if wbs_valid && wbs_ctrl.rwb_en {
regfile[wbs_rd_addr] = wbs_wb_data;
}
}
最後に、命令をFIFOから取り出します。 WBステージでは命令を複数クロックで処理することはなく、 WBステージの次のステージを待つ必要もありません。 wbq_rreadyに1を割り当てることで、 常にFIFOから命令を取り出します(リスト20)。
▼リスト7.20: 命令をFIFOから取り出す (core.veryl) 差分をみる
always_comb {
// WB -> END
wbq_rready = 1;
}
これで、IF、ID、EX、MEM、WBステージを作成できました。
デバッグのために情報を表示する
今までは同時に1つの命令しか処理していませんでしたが、 これからは全てのステージで別の命令を処理することになります。 デバッグ表示を変更しておきましょう。
リスト21のように、デバッグ表示のalways_ffブロックを変更します。
▼リスト7.21: 各ステージの情報をデバッグ表示する (core.veryl) 差分をみる
///////////////////////////////// DEBUG /////////////////////////////////
var clock_count: u64;
always_ff {
if_reset {
clock_count = 1;
} else {
clock_count = clock_count + 1;
$display("");
$display("# %d", clock_count);
$display("IF ------");
$display(" pc : %h", if_pc);
$display(" is req : %b", if_is_requested);
$display(" pc req : %h", if_pc_requested);
$display("ID ------");
if ids_valid {
$display(" %h : %h", ids_pc, if_fifo_rdata.bits);
$display(" itype : %b", ids_ctrl.itype);
$display(" imm : %h", ids_imm);
}
$display("EX -----");
if exs_valid {
$display(" %h : %h", exq_rdata.addr, exq_rdata.bits);
$display(" op1 : %h", exs_op1);
$display(" op2 : %h", exs_op2);
$display(" alu : %h", exs_alu_result);
if inst_is_br(exs_ctrl) {
$display(" br take : %b", exs_brunit_take);
}
}
$display("MEM -----");
if mems_valid {
$display(" %h : %h", memq_rdata.addr, memq_rdata.bits);
$display(" mem stall : %b", memu_stall);
$display(" mem rdata : %h", memu_rdata);
if mems_ctrl.is_csr {
$display(" csr rdata : %h", csru_rdata);
$display(" csr trap : %b", csru_raise_trap);
$display(" csr vec : %h", csru_trap_vector);
}
if memq_rdata.br_taken {
$display(" JUMP TO : %h", memq_rdata.jump_addr);
}
}
$display("WB ----");
if wbs_valid {
$display(" %h : %h", wbq_rdata.addr, wbq_rdata.bits);
if wbs_ctrl.rwb_en {
$display(" reg[%d] <= %h", wbs_rd_addr, wbs_wb_data);
}
}
}
}
パイプライン処理をテストする
それでは、riscv-testsを実行してみましょう。 試しに、RV64IのADDのテストを実行します。
▼リスト7.22: パイプライン処理のテスト
$ make build
$ make sim VERILATOR_FLAGS="-DTEST_MODE"
$ python3 test/test.py -r obj_dir/sim test/share rv64ui-p-add.bin.hex
FAIL : ~/core/test/share/riscv-tests/isa/rv64ui-p-add.bin.hex
Test Result : 0 / 1
おや? テストに失敗してしまいました。 一体何が起きているのでしょうか?
データ依存の対処
正しく動かないプログラムを確認する
実は、ただIF、ID、EX、MEM、WBステージに処理を分割するだけでは、 正しく命令を実行できません。 例えば、リスト23のようなプログラムは正しく動きません。
test/sample_datahazard.hexを作成し、次のように記述します (リスト23)。
▼リスト7.23: sample_datahazard.hex 差分をみる
0010811300100093 // 0:addi x1, x0, 1 4: addi x2, x1, 1
このプログラムでは、 x1にx0 + 1を代入した後、x2にx1 + 1を代入します。 シミュレータを実行し、どのように実行されるかを確かめます(リスト24)。
▼リスト7.24: sample_datahazard.hexを実行する
$ make build
$ make sim
$ ./obj_dir/sim test/sample_datahazard.hex 7
...
# 5
ID ------
0000000000000004 : 00108113
itype : 000010
imm : 0000000000000001
EX -----
0000000000000000 : 00100093
op1 : 0000000000000000 ← x0
op2 : 0000000000000001 ← 即値
alu : 0000000000000001 ← ゼロレジスタ + 1 = 1
# 6
ID ------
0000000000000008 : 00000000
itype : 000000
imm : 0000000000000000
EX -----
0000000000000004 : 00108113
op1 : 0000000000000000 ← x1
op2 : 0000000000000001 ← 即値
alu : 0000000000000001 ← x1 + 1 = 2のはずだが1になっている
MEM -----
0000000000000000 : 00100093
...
ログを確認すると、 アドレス0の命令でx1が1になっているはずですが、 アドレス4の命令でx1を読み込むときにx1は0になっています。
この問題は、 まだアドレス0の命令の結果がレジスタファイルに書き込まれていないのに、 アドレス4の命令でレジスタファイルで結果を読み出しているために発生しています。
データ依存とは何か?
ある命令Aの実行結果の値を利用する命令Bが存在するとき、 命令Aと命令Bの間にはデータ依存(data dependence)があると呼びます。 データ依存に対処するためには、 命令Aの結果がレジスタに書き込まれるのを待つ必要があります。 データ依存があることにより発生するパイプラインハザードのことを データハザード(data hazard)と呼びます。
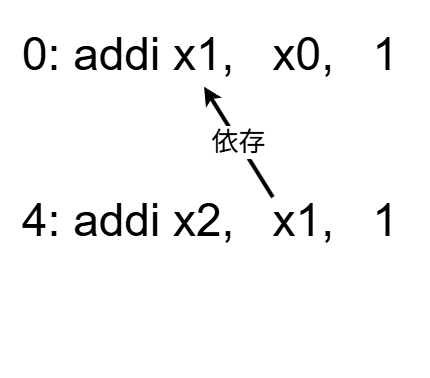
▲図7: データ依存関係のあるプログラム
データ依存に対処する
レジスタの値を読み出すのはEXステージです。 データ依存に対処するために、 データ依存関係があるときにEXステージをストールさせます。
まず、MEMとEXか、WBとEXステージにある命令の間にデータ依存があることを検知します ( リスト25、 リスト26、 リスト27 )。 例えばMEMステージとデータ依存の関係にあるとき、 MEMステージの命令はライトバックする命令で、 rdがEXステージのrs1、またはrs2と一致しています。
▼リスト7.25: データ依存の検知 (core.veryl) 差分をみる
// データハザード
var exs_mem_data_hazard: logic;
var exs_wb_data_hazard : logic;
let exs_data_hazard : logic = exs_mem_data_hazard || exs_wb_data_hazard;
▼リスト7.26: MEMステージとのデータ依存の検知 (core.veryl) 差分をみる
always_comb {
control_hazard = mems_valid && (csru_raise_trap || mems_ctrl.is_jump || memq_rdata.br_taken);
control_hazard_pc_next = if csru_raise_trap ? csru_trap_vector : memq_rdata.jump_addr;
exs_mem_data_hazard = mems_valid && mems_ctrl.rwb_en && (mems_rd_addr == exs_rs1_addr || mems_rd_addr == exs_rs2_addr);
}
▼リスト7.27: WBステージとのデータ依存の検知 (core.veryl) 差分をみる
always_comb {
exs_wb_data_hazard = wbs_valid && wbs_ctrl.rwb_en && (wbs_rd_addr == exs_rs1_addr || wbs_rd_addr == exs_rs2_addr);
}
次に、データ依存があるときに、データハザードを発生させます (リスト28)。 データハザードを起こすためには、 EXステージのFIFOのrreadyとMEMステージのwvalidに、 データハザードが発生していないという条件を加えます。
▼リスト7.28: データ依存があるときにデータハザードを起こす (core.veryl) 差分をみる
always_comb {
// EX -> MEM
exq_rready = memq_wready && !exs_data_hazard;
memq_wvalid = exq_rvalid && !exs_data_hazard;
最後に、データハザードが発生しているかどうかをデバッグ表示します (リスト29)。
▼リスト7.29: データハザードが発生しているかをデバッグ表示する (core.veryl) 差分をみる
$display("EX -----");
if exs_valid {
$display(" %h : %h", exq_rdata.addr, exq_rdata.bits);
$display(" op1 : %h", exs_op1);
$display(" op2 : %h", exs_op2);
$display(" alu : %h", exs_alu_result);
$display(" dhazard : %b", exs_data_hazard);
パイプライン処理をテストする
test/sample_datahazard.hexが正しく動くことを確認します。
▼リスト7.30: sample_datahazard.hexが正しく動くことを確認する
$ make build
$ make sim
$ ./obj_dir/sim test/sample_datahazard.hex 7
...
# 5
...
ID ------
0000000000000004 : 00108113
itype : 000010
imm : 0000000000000001
EX -----
0000000000000000 : 00100093
op1 : 0000000000000000
op2 : 0000000000000001
alu : 0000000000000001
dhazard : 0
...
# 6
...
EX -----
0000000000000004 : 00108113
op1 : 0000000000000000
op2 : 0000000000000001
alu : 0000000000000001
dhazard : 1 ← データハザードが発生している
MEM -----
0000000000000000 : 00100093
mem stall : 0
mem rdata : 0000000000000000
WB ----
# 7
...
EX -----
0000000000000004 : 00108113
op1 : 0000000000000000
op2 : 0000000000000001
alu : 0000000000000001
dhazard : 1
MEM -----
WB ----
0000000000000000 : 00100093
reg[ 1] <= 0000000000000001 ← 1が書き込まれる
# 8
...
EX -----
0000000000000004 : 00108113
op1 : 0000000000000001 ← x1=1が読み込まれた
op2 : 0000000000000001
alu : 0000000000000002 ← 正しい計算が行われている
dhazard : 0 ← データハザードが解消された
MEM -----
WB ----
アドレス4の命令が、 6クロック目と7クロック目にEXステージでデータハザードが発生し、 アドレス0の命令が実行終了するのを待っているのを確認できます。
RV64Iのriscv-testsも実行します。
▼リスト7.31: riscv-testsを実行する
$ make build
$ make sim VERILATOR_FLAGS="-DTEST_MODE"
$ python3 test/test.py -r obj_dir/sim test/share rv64ui-p-
...
FAIL : ~/core/test/share/riscv-tests/isa/rv64ui-p-ma_data.bin.hex
...
Test Result : 51 / 52
正しくパイプライン処理が動いていることを確認できました。